Mining the Social Web, 2nd Edition
Chapter 1: Mining Twitter: Exploring Trending Topics, Discovering What People Are Talking About, and More
This IPython Notebook provides an interactive way to follow along with and explore the numbered examples from Mining the Social Web (2nd Edition). The intent behind this notebook is to reinforce the concepts from the sample code in a fun, convenient, and effective way. This notebook assumes that you are reading along with the book and have the context of the discussion as you work through these exercises.
In the somewhat unlikely event that you've somehow stumbled across this notebook outside of its context on GitHub, you can find the full source code repository here.
Copyright and Licensing
You are free to use or adapt this notebook for any purpose you'd like. However, please respect the Simplified BSD License that governs its use.
Twitter implements OAuth 1.0A as its standard authentication mechanism, and in order to use it to make requests to Twitter's API, you'll need to go to https://dev.twitter.com/apps and create a sample application. There are four primary identifiers you'll need to note for an OAuth 1.0A workflow: consumer key, consumer secret, access token, and access token secret. Note that you will need an ordinary Twitter account in order to login, create an app, and get these credentials.
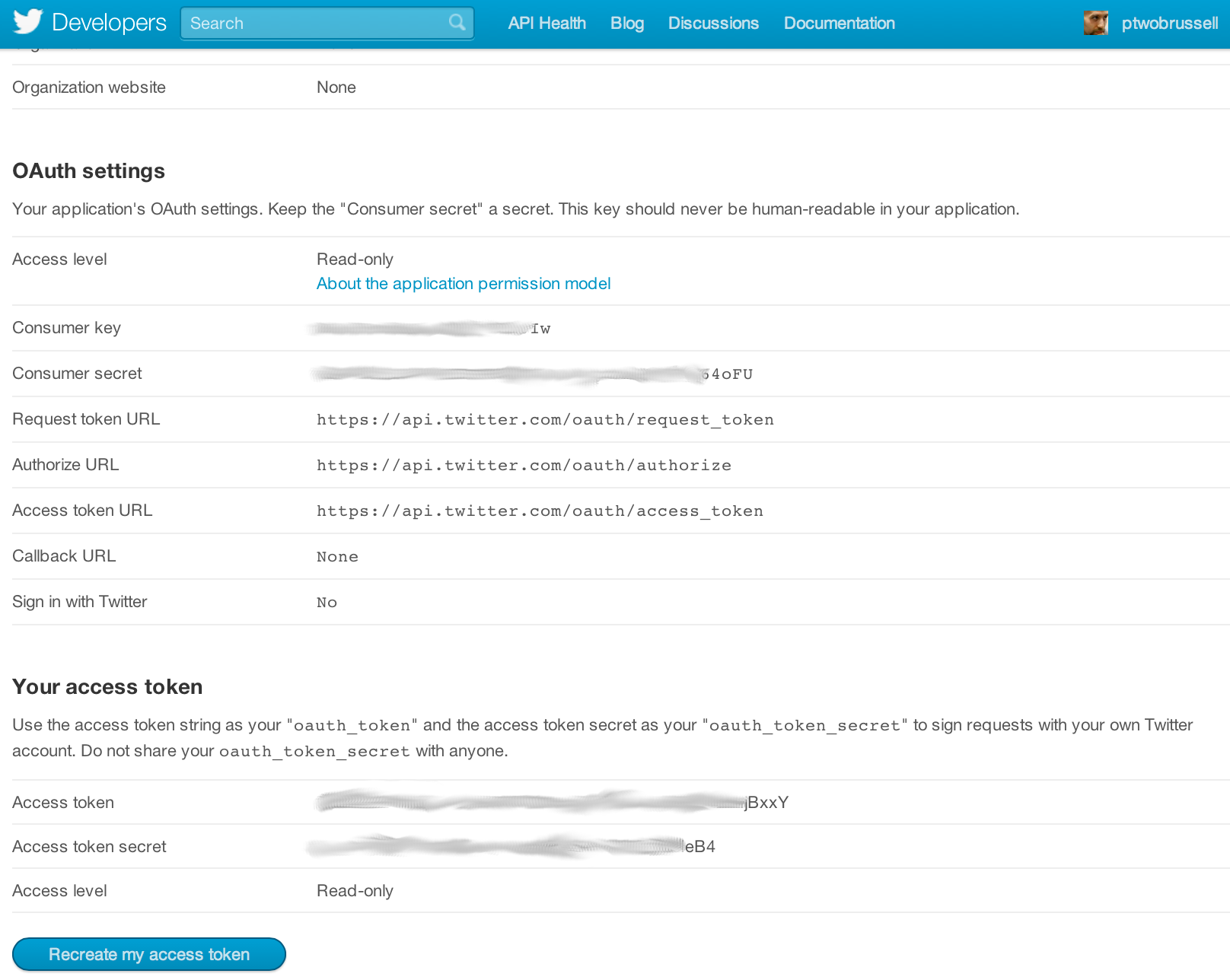
If you are taking advantage of the virtual machine experience for this chapter that is powered by Vagrant, you should just be able to execute the code in this notebook without any worries whatsoever about installing dependencies. If you are running the code from your own development envioronment, however, be advised that these examples in this chapter take advantage of a Python package called twitter to make API calls. You can install this package in a terminal with pip with the command pip install twitter, preferably from within a Python virtual environment.
Once installed, you should be able to open up a Python interpreter (or better yet, your IPython interpreter) and get rolling.
Note: Should you desire to do so, you can load the same set of search results that are illustrated in the text of Mining the Social Web by executing the code below that reads a snapshot of the data and stores it into the same statuses variable as was defined above. Alternatively, you can choose to skip execution of this cell in order to follow along with your own data.
Note: This histogram gives you an idea of how many times tweets are retweeted with the x-axis defining partitions for tweets that have been retweeted some number of times and the y-axis telling you how many tweets fell into each bin. For example, a y-axis value of 5 for the "15-20 bin" on the x-axis means that there were 5 tweets that were retweeted between 15 and 20 times.
Here's another variation that transforms the data using the (automatically imported from numpy) log function in order to improve the resolution of the plot.